






Les compteurs de performance indispensable pour votre serveur Windows
Voici un tutoriel pour créer les compteurs de performance concernant la supervision de base des systèmes d’exploitation.
Selon le rôle du serveur (SQL, Exchange, ADFS, etc) ces compteurs seront à adaptés, mais ils donnent déjà une bonne base pour créer une baseline, pour du troubleshooting, ou du monitoring.
Bien sûr, les seuils d’alerte que j’ai choisis et indiqués sont donnés à titre indicatifs et sont à modifier encore une fois en fonction du rôle des serveurs et du dimensionnement des infrastructures afin de limiter la remontée de faux positifs.
Processeurs
Un thread peut s’exécuter dans l’un des 2 modes suivants :
- Privileged Mode : Synonyme de Kernel Mode.
Le code en cours d’exécution a accès à toutes les zones mémoire et toutes les instructions des CPU peuvent être utilisées.
Le système d’exploitation (services système, drivers…) tourne en Kernel Mode.
- User Mode : C’est le mode « non-privilégié » du CPU.
Il sert à l’exécution du code des applications. L’accès au système est limité dans ce mode.
Quand une application doit par exemple écrire dans un fichier, elle passe du mode User au mode Kernel. A noter également que pour les serveurs de fichiers et les serveurs d’impression, l’essentiel de la charge est traitée en mode Kernel.
Le compteur Processor(*)\%Privileged Time correspond donc pour chaque processeur, au pourcentage de temps de traitement passé en Privileged Mode.
Processor(*)\%User time rapporte le pourcentage de temps de traitement en User Mode et Processor(*)\%Processor Time est la somme des 2 compteurs.
En cas d’incident, on peut analyser processus par processus le temps passé dans chaque mode avec les compteurs \Process(*)\%Processor Time et \Process(*)\%Privileged Time
Compteurs principaux relatifs aux Processeurs | |||||
Compteurs |
Normal |
Warning |
Critical |
||
|
\Processor(*)\% Processor Time (Somme de % Privileged Time et % User Time) |
< 50% |
50–80% |
> 80% |
||
\Processor(*)\% Privileged Time (Temps processeur alloué au kernel) |
< 30% |
30–50% |
> 50% |
||
Compteurs secondaires relatifs aux Processeurs | |||||
Compteurs |
Normal |
Warning |
Critical |
||
\Processor(*)\% Interrupt Time |
< 10% |
10–20% |
> 20% |
||
\Processor(*)\% DPC Time |
< 10% |
10–20% |
> 20% |
||
\System\Context Switches/sec (Nombre de fois où le processeur a changé de thread, à mettre en corrélation avec un haut % Privileged Time) |
< 5,000 |
> 2,500 x NbreDeProcesseurs |
5,000 x NbreDeProcesseurs ou > 20,000 |
||
Le compteur Processor(*)\%Interrupt Time correspond au pourcentage de temps passé à émettre une requête d’entrée/sortie (requête d’entrée/sortie aux périphériques, disques, réseau par exemple) et de la scheduler (l’envoyer en traitement au CPU). Cela ne correspond pas au temps de traitement de l’opération d’entrée/sortie.
L’acronyme DPC correspond à Deferred Procedure Calls. Ce sont des routines effectuant la plupart du travail de gestion des interruptions matériel. Ainsi, \Processor(*)\%DPC Time est le pourcentage de temps passé par le processeur à recevoir et traiter les DPCs.
Une machine doit passer très peu de temps à traiter des interruptions matérielles. On peut déterminer que si %Privileged Time occupe plus de 20% de temps processeur (sur n’importe lequel des cœurs possibles) et si le compteur %DPC Time ou %Interrupt Time occupent 20% de temps de traitement sur le même processeur alors il faut rechercher des problèmes matériel (vérifier s' il y a des mises à jour de drivers disponibles également)
Concernant le compteur \System\Context Switches/sec il représente la fréquence à laquelle les processeurs de la machine passent d’un thread en cours d’exécution à un autre. Si la valeur de ce compteur est élevée, cela peut être causé par un grand nombre d’I/O disque ou réseau, trop de threads actifs (etc…) entre autres choses.
La valeur retournée par ce compteur est à diviser par le nombre de processeurs ou de cœurs
Si on prend l’exemple d’une contention liée aux disques, en cas de lenteurs pour traiter les données à lire ou écrire, le processeur peut allouer son temps de traitement à un autre thread.
Pour améliorer l’efficacité d’un processeur, il faut essayer de réduire le nombre de threads actifs à un instant donné ou augmenter le nombre de cycles d’horloge qu’un thread peut occuper sur un processeur. Le nombre de cycles d’horloge qu’un thread utilise sur un processeur est appelé Quantum. On peut ajuster ce Quantum en jouant sur le paramètre « Adjust for best performance of background services ». Avec cette configuration, les threads peuvent obtenir de grands quantums de temps et donc réduire le temps d’attente pour obtenir à nouveau du temps processeur et par conséquent réduire le nombre de Context Switches.
Mémoire
Compteurs principaux relatifs à la mémoire (virtuelle et physique) | ||||
Compteurs |
Normal |
Warning |
Critical |
|
\Memory\Free System Page Table Entries |
> 12,000 |
8,000–12,000 |
< 8,000 |
|
\Memory\Pool Paged Bytes |
0–50% de la valeur Max |
60–80% de la valeur Max |
80–100% de la valeur Max |
|
\Memory\Pool Nonpaged Bytes |
0–50% de la valeur Max |
60–80% de la valeur Max |
80–100% de la valeur Max |
|
\Memory\Available Mbytes |
> 10% RAM Total |
< 5% RAM Total |
< 1% RAM Total |
|
\Memory\% Committed Bytes In Use |
< 50% |
60-80% |
> 80% |
|
|
|
|
|
|
Compteurs mémoire (virtuelle et physique) secondaires | ||||
Compteurs |
Normal |
Warning |
Critical |
|
\Process(_Total)\Working Set |
Si Available Mbytes > 10% RAM Total |
Si Available Mbytes < 10% RAM ET \Process(_Total)\Working Set est à 60-80% de la RAM |
Available Mbytes est < 10% RAM ET \Process(_Total)\Working Set > 80% de la RAM |
|
\Memory\Pages/sec |
Investiguer si > 2500 pendant une longue période ou à mettre en relation avec une faible valeur du compteur \Memory\Available Mbytes |
|||
Chaque processus possède son propre espace d’adressage virtuel privé qui est une quantité finie de mémoire virtuelle mais les adresses mémoire sont exactement les mêmes pour toutes les applications. Cela permet au système de gérer efficacement les ressources mémoire physiques (RAM + page file).
Si chaque processus possède son propre espace d’adressage pour faire tourner une application, ce n'est n’est pas le cas du noyau (Kernel). La mémoire allouée au Kernel est partagée entre tous les processus.
Un processus donné utilise rarement toute la mémoire qui lui est réservée. Le système gère l’attribution des ressources en fonction des besoins des applications et non ce qu’elles demandent et un processus ne peut déborder de son espace d’adressage mémoire sous peine de crash applicatif.
Quand un processus commit (ou écrit en mémoire), le système alloue au processus l’espace en RAM nécessaire pour stocker les données et cela n’est fait que si le process utilise la mémoire. L’OS gère toute la mémoire que les process ou le noyau utilisent réellement (commited)
Sur un système 32bits :
· Chaque application peut utiliser jusqu’à 2Go
· Le noyau Windows a sur l’ensemble du système jusqu’à 2Go

Chaque application 32bits utilise les mêmes adresses mémoire (de 0x00000000 à 0x7FFFFFFF). Les applications n’écrasent pas pour autant les données des autres en cours d’exécution.

Sur un système 64bits :
· Chaque application peut utiliser jusqu’à 8To
· Le noyau Windows a jusqu’à 8To d’espace

Dans les 2 cas, ce n’est pas parce qu’une application réserve un espace mémoire qu’il y a effectivement des données écrites à ces adresses. Le Kernel n’alloue de la mémoire physique qu’en cas de nécessité. Si l’OS n’a pas assez de mémoire physique pour satisfaire la demande, il devra swapper, écrire dans le page file la mémoire « commited ».
La plus petite unité de mémoire utilisée par un process ou par le système est la page mémoire d’une taille de 4Ko. Les pages mémoire ont 3 états possibles : réserved, commited et free.
Quand un process est créé, la plus grande partie des pages composant l’espace mémoire alloué sont free. Quand une application a besoin de mémoire, elle réserve des pages mémoire (exemple : déclaration d’un tableau de X cases) et à l’écriture de données, les pages sont commited (en RAM ou sur le page file selon la situation). Quand la donnée est écrite, il y a une correspondance faite entre la page mémoire de la mémoire virtuelle du process et une page physique en RAM. L’ensemble de la mémoire utilisée (commited) est appelé « system commit charge »

Le Task Manager de Windows remonte à la ligne Commit (MB), la commit charge représentant l’utilisation actuelle de la mémoire virtuelle par rapport à la mémoire virtuelle totale (RAM+page file = Commit Limit). A noter que si la commit charge a une valeur supérieure à la taille de la RAM installée, alors le page file est en cours d’utilisation.
C’est ce rapport entre Commit Charge et Commit Limit qui est remonté par le compteur de performance \Memory\% Committed Bytes in Use. Plus le pourcentage remonté est élevé, moins le système a de ressources mémoire disponibles (RAM+page file). On peut utiliser le compteur \Process(*)\Private Bytes pour identifier le process consommant le plus de Committed memory. (La mémoire « privée » d’un process ne peut être utilisée par un autre)
Pour en revenir aux compteurs relatifs à la mémoire listés plus haut, il faut définir les notions suivantes :
- Nonpaged Pool : Le Kernel et les drivers utilisent cet espace mémoire pour des données devant rester en mémoire physique (RAM). On y trouve le Kernel lui-même, des objets représentant les process et les threads, les mutexes, les semaphores etc…
- Paged Pool : Correspond aux pages mémoire pouvant être stockées dans le page file, permettant ainsi à l’espace mémoire occupé en RAM d’être réutilisable.

Quand un driver ou le système font référence à une page mémoire se trouvant sur le page file, il se produit une opération appelée « page fault » autorisant le memory manager à recharger cette page en RAM. Le plus gros consommateur du paged pool est depuis Vista (et les OS suivants) la base de registre. Les serveurs de fichiers et d’impression sont aussi très consommateurs de cet espace mémoire. On peut observer des pics d’utilisation lorsqu’un grand nombre d’utilisateurs accèdent à leurs fichiers ou quand un grand nombre d’impressions sont lancées en simultané.
Dans l’espace mémoire utilisateur, toute les pages mémoire présentes en RAM peuvent être placées dans le page file si besoin. (Certaines applications peuvent exploiter la local policy Lock Pages in memory pour bloquer certains pools mémoire en RAM)
Sur Windows Server 2003 R2 et les OS précédents, les pools mémoire non paginés (Nonpaged) et paginées (paged) sont verrouillés dans des portions spécifiques de la mémoire.

Ainsi, la mémoire paginée peut être à court de ressources si elle est utilisée de façon intensive et ne pourrait pas utiliser de l’espace mémoire disponible dans la partie non-paged.
La taille allouée à chaque pool mémoire est définie lors du boot de la machine, en fonction de la quantité de RAM installée.
A partir de Windows Server 2008 et uniquement pour les éditions 32bits, la mémoire virtuelle allouée au Kernel est dynamique. Un pool mémoire peut utiliser l’espace disponible d’un autre pool. Le système a alors moins de risques d’être à court de mémoire dédiée au noyau.

Il est alors important de superviser les compteurs \Memory\Pool Paged Bytes et \Memory Pool Nonpaged Byte pour les OS Windows Server 2003 64bits mais surtout 32bits.
Le calcul de la valeur maximum du paged pool pour Windows Server 2008 et les versions suivantes suit la règle :
|
32-bit |
64-bit |
|
Vista, Server 2008, Windows 7, Server 2008 R2, 2012 et + (pas de version 32bits de Windows Server 2008 R2) |
min( system commit limit, 2GB) |
min( system commit limit, 128GB) |
Pour le calcul de la valeur maximum du nonpaged pool à partir de Windows Server 2008, la règle suivante est appliquée :
|
32-bit |
64-bit |
|
Vista, Server 2008, Windows 7, Server 2008 R2, 2012 et + (pas de version 32bits de Windows Server 2008 R2) |
min( ~75% of RAM, 2GB) |
min(~75% of RAM, 128GB) |
Voici les tableaux de référence pour Windows Server 2003 avec les valeurs de Paged Pool, Non Paged Pool et de PTE en fonction de l’architecture et de la quantité de RAM installée :
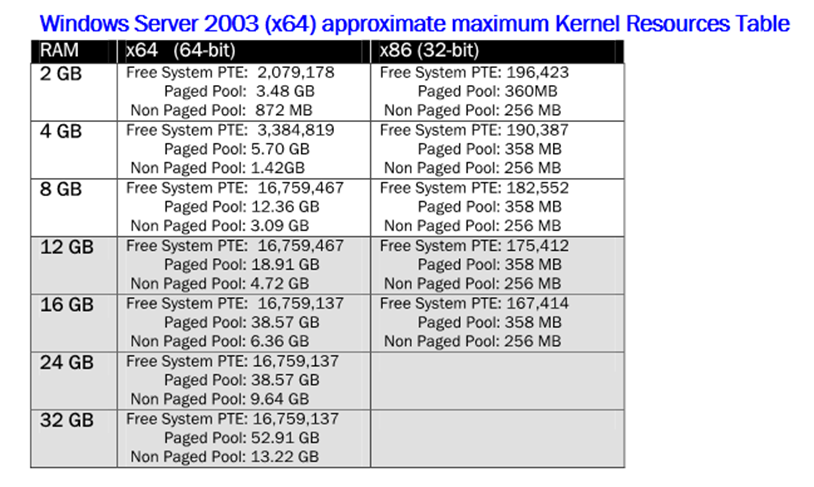
Comme évoqué précédemment, il existe un mécanisme faisant la correspondance entre les pages mémoire virtuelles et les pages en mémoire physique. Ce sont les « Page Table Entries » ou PTE qui permettent ce mapping de ressources. Un manque de PTE peut bloquer tout le système. Comme les PTE se servent en dernier de l’espace mémoire alloué au Kernel, c’est-à-dire qu’elles occupent l’espace restant (voir le schéma ci-dessus pour visualiser les autres ressources partageant le même espace), un manque de PTE implique un manque de mémoire virtuelle pour le Kernel.
Le suivi du nombre de PTE disponible se fait grâce au compteur de performance \Memory\Free System Page Table Entries.
Le « Working Set » d’un process est la quantité de RAM utilisée par ce process. La taille du « Working Set » est gérée par le Kernel et peut être réduit ou augmenté selon la fréquence d’utilisation des données.
Enfin, une « page fault » se produit lorsque l’on essaie d’accéder à une page mémoire et que cette page ne se trouve pas dans le Working Set du process. Une page fault est dite soft quand la page est ailleurs en RAM et on parle de hard page fault si la page mémoire est sur le disque, pas nécessairement dans le page file.
Le compteur de performance Memory\Pages/sec mesure le nombre de hard page fault par seconde. Lors d’une analyse, il est à utiliser en combinaison de \Memory\Available MBytes qui représente la quantité de RAM immédiatement disponible.
Quand le Working Set d’un process est réduit d’une manière agressive parce que le système a besoin de libérer de la mémoire, un grand nombre de hard page fault peut arriver lors de l’écriture des pages mémoire peu utilisées sur le disque.
1.1.2 Disques
Compteurs principaux relatifs aux Disques | |||
Compteurs |
Normal |
Warning |
Critical |
\LogicalDisk(*)\Avg. Disk sec/Read |
< 15 ms |
> 15 ms |
> 25 ms |
\LogicalDisk(*)\Avg. Disk sec/Write |
< 15 ms |
> 15 ms |
> 25 ms |
\PhysicalDisk(*)\Avg. Disk sec/Read |
< 15 ms |
> 15 ms |
> 25 ms |
\PhysicalDisk(*)\Avg. Disk sec/Write |
< 15 ms |
> 15 ms |
> 25 ms |
\LogicalDisk(*)\% Free Space |
> 10% |
< 10% |
< 5% |
Compteurs Disque secondaires | |||
\LogicalDisk(*)\Avg. Disk Queue Length |
Tirer un graphe de ces compteurs avec Perfmon par exemple et étudier les tendances en cas d'incident. En tout état de cause, la valeur doit être inférieure à la Queue Depth paramétrée sur les cartes HBA (32 par défaut pour la plupart des constructeurs) |
||
\PhysicalDisk(*)\Avg. Disk Queue Length | |||
\LogicalDisk(*)\Current Disk Queue Length | |||
\LogicalDisk(*)\Current Disk Queue Length | |||
Les compteurs de performance de type PhysicalDisk permettent de mesurer les performances des LUNs attachées au système. (Exemple : 07(D:, E: )
Les compteurs de performance de type LogicalDisk permettent de mesurer les performances des volumes ou lecteurs de la machine (ceux ayant une lettre d’attribuée : C:, D:, E: …)

Chaque disque à une file d’attente ou disk queue dont la taille correspond au nombre de requête d’entrée sortie en attente ou en cours de traitement par le disque. Plusieurs I/O peuvent être traitée en même temps en fonction du sous-système disque et ces I/O ne sont pas nécessairement traitées dans l’ordre où elles sont arrivées.
C’est le compteur de performance Avg. Disk Queue Length qui représente le nombre moyen d’I/O en lecture/écriture en attente ou entre cours de traitement. Comme le traitement des I/O est dépendant du matériel hébergeant les données et de son temps de réponse, on ne peut définir de seuil d’alerte pour ce compteur.
Pour les objets LogicalDisk ou PhysicalDisk, les compteurs Avg. Disk sec/Read et Avg. Disk sec/Write représentent le temps moyen en secondes de chaque opération respectivement de lecture et d’écriture. Ces compteurs mesurent le temps de réponse de chaque I/O et en calculent la moyenne entre chaque valeur. Cela correspond à la notion de temps de réponse du sous-système disque. |
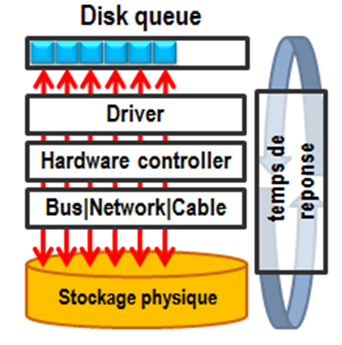
Si le sous-système disque est en mesure de tenir la charge induite par les demandes d’I/O, les temps de réponse doivent être aussi rapides ou plus rapides que le temps d’accès aux disques. S’il y a plus de requêtes dans la disk queue que ne peux en gérer le disque, le temps de réponse augmentera en conséquence.
La valeur de 15ms recommandée comme seuil d’alerte est basé sur le temps de réponse pour des I/O de 64Ko ou moins. A titre indicatif, un disque de 7200tr/mn a en général un temps de réponse de l’ordre de 13ms.
Si l’on observe des performances inférieures à ce qui était attendu compte tenu du matériel et de l’infrastructure mise en place :
- Vérifier les éventuels problèmes matériels
- Vérifier la taille des I/O supérieures à 64Ko (compteur de perf nommé Avg. Disk Bytes/Read et Avg. Disk Bytes/Write pour les objets LogicalDisk et PhysicalDisk)
- Vérifier la fragmentation des disques
- Ajuster la tâche du cache au niveau stockage
- Voir la possibilité d’utiliser un sous-système disque plus performant pour tenir la charge ou réduire les I/O peut être inutiles.
1.1.3 Réseau
Compteurs principaux relatifs au réseau | |||
Compteurs |
Normal |
Warning |
Critical |
\Network Interface(*)\Current Bandwidth (bits per second) |
Attention : La valeur remontée tiens compte du teaming eventuellement configuré sur les interfaces réseau. La valeur peut donc être le double de celle attendue ! |
||
\Network Interface(*)\Bytes Sent/sec |
A grapher |
||
\Network Interface(*)\Bytes Received/sec |
A grapher |
||
% Network utilization for outbound traffic = ((Bytes Sent/sec * 8) / Current Bandwidth) * 100 (A calculer à partir des compteurs ci-dessus) |
< 30 % |
30-60% |
> 60% |
% Network utilization for inbound traffic = ((Bytes Received/sec * 8) / Current Bandwidth) * 100 (A calculer à partir des compteurs ci-dessus) |
< 30 % |
30-60% |
> 60% |
|
\Network Interface(*)\Output Queue Length (Taille de la file de sortie)
|
0 |
1–2 |
> 2 |
Compteurs secondaires relatifs au réseau | |||
\Network Interface(*)\Bytes Total/sec (total of Bytes Sent/sec and Bytes Received/Sec) |
A grapher |
||
\TCPv4(*)\Connections Established (nombre de connexions établies vers cet ordinateur) |
< 3,000 |
> 3,000 |
Si bien supérieur à 3000, alors identifier les sources de ces nombreuses connexions entrantes (netstat -abno par exemple) |
\TCPv4(*)\Connections Active (nombre de connexions établies depuis cet ordinateur) |
A grapher |
||
Le compteur de performance \Network Interface(*)\Output Queue Length mesure le nombre de paquets en attente d’être délivrés sur le réseau. Ce compteur n’indique pas pourquoi des paquets sont « mis en attente », c’est un indicateur à prendre en compte pour pousser plus loin l’investigation.
Le compteur \TCPv4(*)\Connections Established mesure le nombre de connexions TCP dans l’état Established ou CLOSE-WAIT (la commande netstat permet de connaitre l’état des connexions TCP ou UDP sur une machine). On peut arriver à des situations où tous les ports disponibles sur la machines sont consommés, entrainant alors des problèmes d’authentification ou d’accès aux applications hébergées sur le serveur.
Le compteur \TCPv4(*)\Connections Active remonte le nombre de fois où une connexion est passée de l’état SYN-SENT à l’état CLOSED. Ce sont les connexions ouvertes depuis la machine. Ce compteur est cumulatif et permet d’estimer sur l’intervalle de collecte le taux d’ouverture de connexions TCP.